24 Cours Apprentissage automatique
Apprentissage automatique⚓︎
Un programme informatique a pour objectif de résoudre un problème dont on connaît les entrées possibles, et comment trouver la solution en fonction des entrées. Par exemple, le logiciel Pronote sait calculer la moyenne générale d’un élève à partir de toutes les notes entrées par les professeurs.
Pour les problèmes que l’on ne sait pas résoudre, comme par exemple la reconnaissance automatique des chiffres écrits à la main à partir d’une image scannée, on ne peut pas écrire de programme car on ne sait pas exactement décrire comment reconnaître un 1.
Mais, pour ces problèmes, il est facile d’avoir une base de données regroupant de nombreuses instances du problème considéré.

L’apprentissage automatique consiste alors à écrire un algorithme qui, à partir de données et d’expériences passées, va apprendre à résoudre « au mieux » un problème considéré.
Type de problème⚓︎
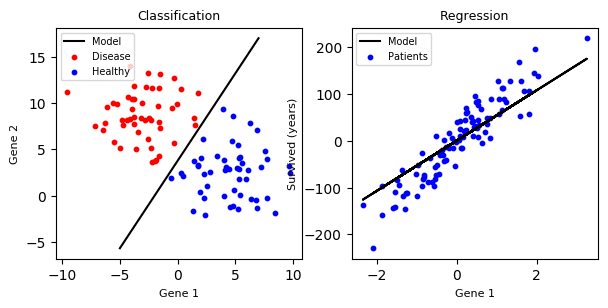
On distingue les algorithmes de classification de ceux de régression.
L’exemple précédent est un algorithme de classification : un symbole dessiné est un "1", ou un "2", ou autre chose. Mais il n'existe pas de symbole qui soit un peu "1", un peu "2"... Les "classes" obtenues sont des valeurs discrètes (au sens bien séparées).
Un algorithme de régression permet, quant à lui, d’obtenir un nombre réel. Par exemple, à partir d’un échantillon contenant les données des habitations d’une ville (quartier, superficie, prix, etc.), l’algorithme sera en mesure de proposer un prix pour une nouvelle habitation.
Mode d’apprentissage⚓︎
On distingue les algorithmes supervisés des algorithmes non supervisés.
Prenons un exemple d’images représentant des chats ou des chiens.

- S’il s’agit d’un algorithme supervisé, c’est alors nous, humains, qui allons proposer les critères de classement (« chat » ou « chien »). Le nombre de classes est connu.
- L’algorithme non supervisé doit par contre trouver lui–même les critères pour les organiser en groupe : on parle alors de clustering.
Démarche⚓︎
Nous allons programmer une phase d'apprentissage à partir des d'un jeu de données dont on connaît la classe (la valeur, suivant le problème).
Puis il y aura une phase de tests pour retenir le meilleur modèle possible par rapport au problème à résoudre : il s'agit d'ajuster les paramètres du modèle au fur et à mesure des différents essais.
Puis, on pourra appliquer le modèle obtenu à des nouvelles données dont on ne connaît pas a priori la classe ou la valeur.
L'objectif de l'apprentissage automatique est alors de minimiser l’erreur des prédictions de l’algorithme.
Attention ! Un premier piège à éviter est d'évaluer la qualité du modèle final en utilisant les mêmes données que celles qui ont servi à l'entraîner. En effet, le modèle est complètement optimisé pour les données à l'aide desquelles il a été créé. L'erreur sera logiquement minimale sur ces données. Alors que l'erreur sera toujours plus élevée sur des données que le modèle n'aura jamais vues.
Répartition des données⚓︎
Pour minimiser ce problème, la meilleure approche est de séparer dès le départ le jeu de données en deux parties distinctes.
Les données d’entraînement⚓︎
Ce jeu de données permet d’entraîner le modèle. C’est celui que l’on vient d’évoquer.
Les données de test⚓︎
Ce jeu de données permet de mesurer l’erreur du modèle final sur des données qu’il n’a jamais vues.
On va simplement passer en paramètre ces données comme s’il s’agissait de données que l’on n’a encore jamais rencontrées (comme cela va se passer ensuite en pratique pour prédire de nouvelles données) et mesurer la performance du modèle sur ces données.
Ce sont des données auxquelles on ne va pas toucher avant la toute fin pour pouvoir être sûr que le modèle fonctionne.
En général, les données sont séparées avec les proportions suivantes : 80 % pour le jeu d’entraînement et 20 % pour le jeu de test.
Algorithmes d’apprentissages automatique⚓︎
Supervisés⚓︎
- Régression linéaire
- Régression logistique
- Classification naïve bayésienne
- Forêts d’arbres de décision
- Machine à vecteurs de support
- Réduction de dimensionnalité
- k plus proches voisins
Non supervisés⚓︎
Algorithme des k-moyennes (k-means)
On classe les données par groupes (clusters) de similarités. On utilise souvent la notion de distance pour faire ces regroupements.
{{< figure src="/ox-hugo/k-means-clustering.jpeg" width="50%" >}}
Exemples d’applications⚓︎
- Médecine : soutien à la décision clinique pour le diagnostic médical
- Finance : trading algorithmique (des millions de transactions par jour sans aucune intervention humaine)
- Police : prévention des crimes et délits
- Justice : aide à la décision dans les cas simples
- Média : analyse de contenu multimédia audiovisuel
- Musique : imitation, dans une certaine mesure, de la composition humaine
-
Services client : assistants en ligne automatisés, souvent représentés par des avatars
-
Jeux vidéo : navigation dynamique des personnages non joueurs
- Transports : voitures autonomes
- Éducation : parcours personnalisés d’apprentissage
- Cybersécurité : prévention des attaques
- Plateformes de streaming : recommandations personnalisées
- GPS : anticipation des embouteillages
- Traduction : analyse sémantique (le sens) d’une phrase
Algorithme des k plus proches voisins⚓︎
L’algorithme des k plus proches voisins est un algorithme d’apprentissage supervisé. Il est souvent noté k-NN pour k-nearest neighbors en anglais.
Lorsqu’on exécute l’algorithme sur une nouvelle donnée, la méthode consiste à prendre en compte les k échantillons d’apprentissage les plus proches pour calculer le résultat. La classe majoritairement représentée sera choisie pour « classer » la nouvelle donnée.
Reprenons l’exemple des images de chiens ou de chats.
- Choisissons
k = 5. Cela signifie que l’algorithme ne va prendre en compte que les cinq images dont les caractéristiques sont les plus proches de l’image à tester.
- Supposons que, parmi ces cinq images, trois sont celles de chats et deux celles de chiens, l’algorithme va donc considérer que la nouvelle image est celle d’un chat.
- On dit parfois que l’on fait « voter » les plus proches voisins.
Dans cet algorithme k-NN, la notion de distance entre échantillons est primordiale et doit être définie en fonction des données et du fonctionnement attendu.
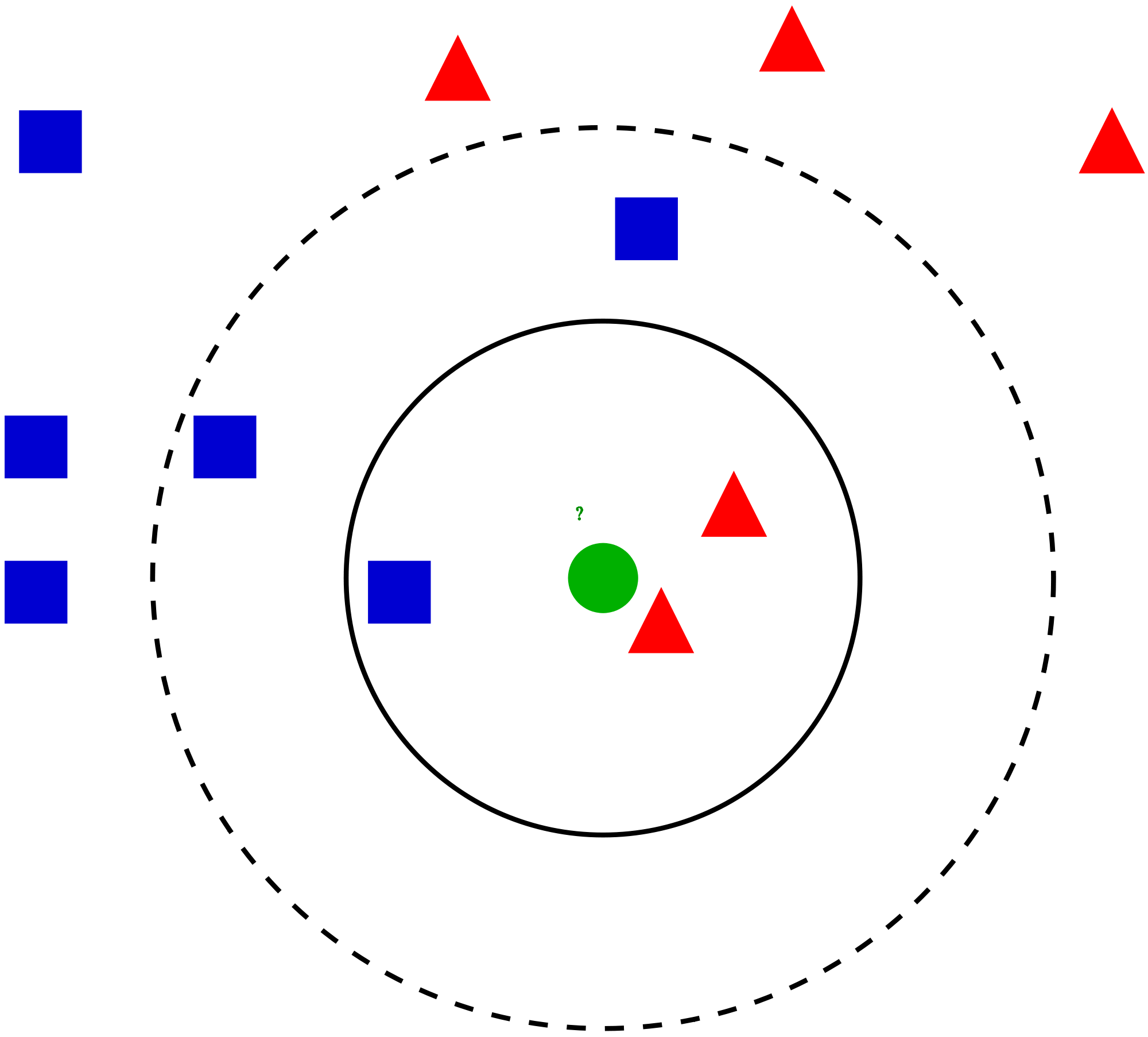
On remarque que si l’on choisit k = 3, l’algorithme classera plutôt la nouvelle image en tant que chien.
Une grande part de l’apprentissage automatique consiste donc à « entraîner » l’algorithme afin de minimiser les erreurs de prédiction.
Pour l’algorithme k-NN, cela consiste, entre autres, à :
- ne choisir que les paramètres pertinents des données (est-il judicieux de prendre en compte le paysage de fond dans les photos de chats et de chiens ?) ;
- choisir le meilleur nombre
kde voisins à faire voter (est-il judicieux de choisir unkpair ? unktrop petit ? unktrop grand ?) ;
- choisir la meilleure formule pour le calcul de la distance (euclidienne, de Manhattan, de Minkowski, de Tchebytchev, etc.).