09 Cours Protocole HTTP
Le principe client-serveur⚓︎
La navigation sur le web se fait suivant le modèle client-serveur :
- le client effectue des requêtes.
- le serveur répond à ces requêtes.
Exemple : Lorsque vous naviguez sur internet :
- le client est votre navigateur ;
- le serveur est un logiciel qui tourne sur un ordinateur en général dédié à cela.
Le serveur⚓︎
De manière générale, on appelle serveur un ordinateur dédié au logiciel serveur qu'il abrite. Ce logiciel reçoit les requêtes des clients puis est exécuté sur l'ordinateur dédié.
Un serveur doit pouvoir répondre aux requêtes d'un grand nombre de clients donc ces ordinateurs sont le plus souvent dotés de capacités supérieures à celles des ordinateurs personnels :
- plus grande puissance de calcul ;
- gestion améliorée des entrées-sorties ;
- davantage de connexions réseau.
Exemples
Il existe une grande variété de logiciels serveurs et de logiciels clients en fonction des besoins à servir :
- un serveur Web publie des pages Web demandées par des navigateurs Web ;
- un serveur de messagerie électronique envoie du courriel à des clients de messagerie ;
- un serveur de fichiers permet de partager des fichiers sur un réseau ;
- un serveur de base de données permet de récupérer des données stockées dans une base de données ;
- etc...
Caractéristiques d'un programme serveur :
- il attend (« écoute ») une connexion entrante sur un ou plusieurs ports réseaux locaux ;
- à la connexion d'un client sur le port en écoute, il ouvre un socket local au système d'exploitation ;
- à la suite de la connexion, le processus serveur communique avec le client selon le protocole prévu par la couche application.
Le client⚓︎
Par extension, le mot « client » désigne à la fois le logiciel qui émet une requête vers un serveur et l'ordinateur (ou la machine virtuelle) sur lequel est exécuté ce logiciel.
Les clients sont souvent des ordinateurs personnels ou des appareils individuels (téléphone, tablette, objets connectés, ...).
Caractéristiques d'un programme client :
- il établit la connexion au serveur à destination d'un ou plusieurs ports réseaux ;
- lorsque la connexion est acceptée par le serveur, il communique comme le prévoit la couche application utilisée.
Serveur web⚓︎
L'expression « Serveur Web » peut faire référence :
- à des composants logiciels (software),
- à des composants matériels (hardware),
- ou à des composants logiciels et matériels qui fonctionnent ensemble.
Composants matériels⚓︎
Physiquement, un serveur web est un ordinateur qui stocke les fichiers constitutifs d'un site web (par exemple les fichiers HTML, les images, les feuilles de style CSS, les fichiers JavaScript,...). Il envoie ces fichiers à l'appareil de l'utilisateur (le client) qui visite le site web.
Cet ordinateur est connecté à Internet et il est généralement accessible via un nom de domaine tel que mozilla.org ou csilyon.fr.
Composants logiciels⚓︎
Un serveur web contient différents fragments qui contrôlent la façon dont les utilisateurs peuvent accéder aux fichiers hébergés.
Un serveur Web contient au moins un serveur HTTP, c'est-à-dire un logiciel qui comprend les URL et le protocole HTTP.
Principe Client-Serveur sur le Web⚓︎
A chaque fois qu'un navigateur a besoin d'un fichier hébergé sur un serveur web, le navigateur demande (on dit qu'il « envoie une requête » ) le fichier via le protocole HTTP.
Quand la requête atteint le bon serveur web (matériel), le serveur HTTP (logiciel) renvoie le document demandé, à nouveau grâce au protocole HTTP.

Dynamique vs statique⚓︎
Pour publier un site web, on peut utiliser un serveur web statique ou un serveur web dynamique.
Serveur web statique :
Ce serveur est composé d'un ordinateur (matériel) et d'un serveur HTTP (logiciel).
Il est appelé « statique » car le serveur envoie les fichiers hébergés « tels quels » vers le navigateur (c'est le cas du site de cours www.info.csilyon.fr).
Serveur web dynamique :
Ce serveur est aussi composé d'un ordinateur (matériel) et d'un serveur HTTP (logiciel).
Mais il possède aussi d'autres composants logiciels dont un serveur d'applications et une base de données.
Il est appelé « dynamique » car le serveur d'applications met à jour les fichiers hébergés avant de les envoyer au navigateur via HTTP.
Exemple :
Afin de produire la page web que vous voyez sur votre navigateur, le serveur d'applications peut utiliser un modèle HTML et le remplir avec des données.
Ainsi, des sites comme MDN ou Wikipédia ont des milliers de pages mais il n'existe pas un document HTML réel pour chacune de ces pages. En fait, il y a quelques modèles (ou gabarits) HTML qui sont utilisés avec une gigantesque base de données.
Cette organisation permet de mieux mettre à disposition le contenu et de maintenir plus efficacement un (gros) site web.
Comment observer le fonctionnement d'un navigateur web ?⚓︎
En utilisant les "Outils de développement web" du navigateur, on peut observer les requêtes dans l'onglet "Réseaux".
On peut par exemple repérer une réponse 404 (j'ai mal orthographié mon url) :
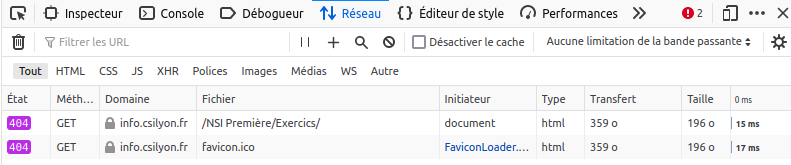
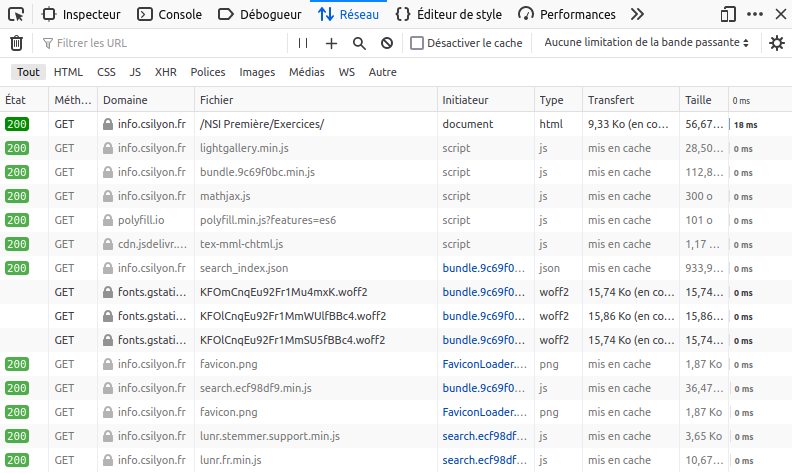
alors qu'une bonne orthographe recevrait des codes 200, et tout le html nécessaire à l'affichage de la page :
Simulateur
Il existe aussi des sites qui permettent de simuler les échanges et de faire apparaître les requêtes et les réponses.
Par exemple, le site httpie.io permet de récupérer ces informations.
On peut, par exemple, lui donner l'instruction http -v GET http://info.csilyon.fr.
Protocole HTTP⚓︎
Le protocole HTTP (acronyme de Hypertext Transfer Protocol) est le protocole réseau utilisé par les navigateurs Web (Firefox, Google Chrome, etc.) et les serveurs Web (Apache, NGINX, etc.) pour communiquer entre eux.
Comme son nom l'indique, ce protocole définit comment transférer des fichiers hypertextes (c'est-à-dire des documents web liés entre eux) entre deux ordinateurs.
C’est lui qui est utilisé par exemple pour obtenir un fichier HTML, une image, poster un formulaire Internet, etc.
C’est un protocole texte (donc lisible en clair) s’appuyant sur les protocoles plus bas-niveau TCP et IP.
Les robots des moteurs de recherche tel que les googlebots qui explorent les sites internet (en anglais crawling) utilisent également le protocole HTTP pour communiquer avec les serveurs Web.
Avec le protocole HTTP la communication entre un navigateur et un serveur Web est finalement assez simple. En voici le déroulé :
- une URL telle que http://www.exemple.com/monDossier/monFichier.html est donnée au navigateur par un internaute ;
- le navigateur en extrait le nom de domaine
www.exemple.comet à partir de cette information sait comment trouver le serveur Web distant (grâce à une opération dite de DNS lookup qui résout un nom de domaine en une adresse IP) ; - à partir de là, une connexion (basée sur les protocoles TCP/IP) est établie entre le navigateur et le serveur Web distant ;
- une requête HTTP demandant la ressource
monFichier.htmlest alors transmise par le navigateur ; - le serveur Web trouve la ressource correspondante et en renvoie le contenu dans une réponse HTTP ;
- le navigateur est désormais capable d’afficher le fichier HTML à l’internaute.
- le serveur ferme la connexion pour signaler la fin de la réponse.
Remarques :
- le client reçoit toujours une réponse à sa requête HTTP, même si celle-ci est un message d'erreur ;
- le serveur ne peut que répondre à la requête d'un client (il n'envoie rien sans sollicitation).
- le protocole HTTP est sans état : ni le serveur, ni le client ne se souviennent des communications précédentes.
Par exemple, si on utilisait uniquement HTTP, un serveur ne pourrait pas se souvenir si un mot de passe a été saisi ou si une transaction est en cours (pour gérer cela, il faut utiliser un serveur d'applications).
Protocole HTTPS⚓︎
Le protocole HTTPS est la version sécurisée du protocole HTTP. Par sécurisé en entend que les données sont chiffrées avant d’être transmises sur le réseau.
Voici les différentes étapes d’une communication client-serveur utilisant le protocole HTTPS :
- le client demande au serveur une connexion sécurisée (en utilisant « https » à la place de « http » dans la barre d’adresse du navigateur web) ;
- le serveur répond au client qu’il est OK pour l’établissement d’une connexion sécurisée. Afin de prouver au client qu’il est bien celui qu’il prétend être, le serveur fournit au client un certificat prouvant son « identité ». En effet, il existe des attaques dites man in the middle, où un serveur-pirate essaye de se faire passer, par exemple, pour le serveur d’une banque : le client, pensant être en communication avec le serveur de sa banque, va saisir son identifiant et son mot de passe, identifiant et mot de passe qui seront récupérés par le serveur pirate. Afin d’éviter ce genre d’attaque, des organismes délivrent donc des certificats prouvant l’identité des sites qui proposent des connexions « https ».
- à partir de ce moment-là, les échanges entre le client et le serveur seront chiffrés grâce à un système de clé de chiffrement (nous aborderons cette notion de clé de chiffrement l’année prochaine, en Terminale). Même si un pirate parvient à intercepter les données circulant entre le client et le serveur, ces dernières ne lui seraient d’aucune utilité, car totalement incompréhensible à cause du chiffrement (seuls le client et le serveur sont aptes à déchiffrer ces données)
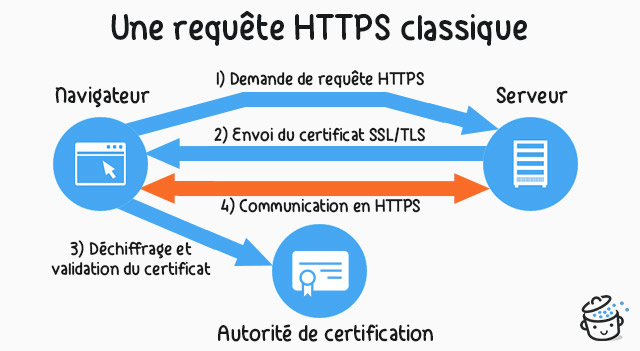
D’un point vu strictement pratique il est nécessaire de bien vérifier que le protocole HTTPS est bien utilisé (l’adresse commence par « https ») avant de transmettre des données sensibles (coordonnées bancaires...). Si ce n’est pas le cas, passez votre chemin, car toute personne qui interceptera les paquets de données sera en mesure de lire vos données sensibles.
Entête HTTP d’une requête⚓︎
Voici un exemple d’entête de requête envoyé par un navigateur :
GET /monDossier/monFichier.html HTTP/1.1
Host: www.exemple.com
User-Agent : Mozilla/5.0
Accept : text/html
Nous avons ici plusieurs informations :
GETest la méthode employée (voir ci-dessous)/mondossier/monFichier.htmlcorrespond à l’URL de la ressource demandéeHTTP/1.1: la version du protocole est la 1.1Hostindique le nom de domaine du serveur et (facultativement) le numéro de port TCP sur lequel le serveur écoute.Mozilla/5.0: le navigateur web employé est Firefox de la société Mozillatext/html: le client s’attend à recevoir du HTML
Une requête HTTP utilise une méthode (c’est une commande qui demande au serveur d’effectuer une certaine action). Voici la liste des méthodes disponibles :
GET, HEAD, POST, OPTIONS, CONNECT, TRACE, PUT, PATCH, DELETE
Détaillons quatre de ces méthodes :
GET: c’est la méthode la plus courante pour demander une ressource. Elle est sans effet sur la ressource.POST: cette méthode est utilisée pour soumettre des données en vue d’un traitement (côté serveur). Typiquement c’est la méthode employée lorsque l’on envoie au serveur les données issues d’un formulaire.DELETE: cette méthode permet de supprimer une ressource sur le serveur.PUT: cette méthode permet de modifier une ressource sur le serveur
Liste des principaux champs HTTP des requêtes⚓︎
Il est utile de connaître les champs HTTP les plus connus pour les requêtes :
| Champ HTTP | Explication |
|---|---|
| Host | c’est le nom du domaine visé. Un serveur Web peut gérer plusieurs domaines en même temps sur la même machine. On dit alors qu’il gère des ’virtual hosts’. |
| User-Agent | ce champ est utilisé par les navigateurs pour indiquer leur nom. Les crawlers des moteurs de recherches utilise aussi ce champ pour se faire reconnaitre (ex: googlebot pour Google) |
| Referer | quand un utilisateur clique sur un lien externe à partir d’une page, le navigateur indique dans ce champ l’URL de la source. Cela peut être très utile pour analyser la source de notre trafic. |
Entête HTTP d’une réponse⚓︎
Voici un exemple d’entête de réponse renvoyé par un serveur Web tel que Apache :
HTTP/1.1 200 OK
Date: Thu, 17 feb 2020 12:02:32 GMT
Server: Apache/2.0.54 (Debian GNU/Linux) DAV/2 SVN/1.1.4
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8
<!doctype html>
<html lang="fr">
<head>
<meta charset="utf-8">
<title>Voici mon site</title>
</head>
<body>
<h1>Ceci est un titre</h1>
<p>Ceci est un <strong>paragraphe</strong>.</p>
</body>
</html>
Commençons par la fin : le serveur renvoie du code HTML. Une fois ce code reçu par le client, il est interprété par le navigateur qui affiche le résultat à l’écran. Cette partie correspond au corps de la réponse.
La première ligne se nomme la ligne de statut : HTTP/1.1 est la version de HTTP utilisé par le serveur.
200 est le code indiquant que le document recherché par le client a bien été trouvé par le serveur. Il existe d’autres codes dont un que vous connaissez peut-être déjà : le code 404 (qui signifie « Le document recherché n’a pu être trouvé »). Ces codes sont détaillés plus loin.
Les cinq lignes suivantes constituent l’en-tête de la réponse, une ligne nous intéresse plus particulièrement :
Server: Apache/2.0.54 (Debian GNU/Linux) DAV/2 SVN/1.1.4
Le serveur Web qui a fourni la réponse http ci-dessus a comme système d’exploitation une distribution GNU/Linux nommée Debian (pour en savoir plus sur GNU/Linux, n’hésitez pas à faire vos propres recherches). Apache est le coeur du serveur web puisque c’est ce logiciel qui va gérer les requêtes http (recevoir les requêtes http en provenance des clients et renvoyer les réponses http). Il existe d’autres logiciels capables de gérer les requêtes http (nginx, lighttpd, etc.) mais Apache est toujours le plus populaire puisqu’il est installé sur environ la moitié des serveurs web mondiaux.
Liste des codes HTTP⚓︎
En tant que simple internaute, on peut être confronté à des codes de réponse HTTP (par exemple quand on tape une URL incorrecte). Voici une description des principales valeurs à connaitre :
| Code HTTP | Explication |
|---|---|
| Code HTTP 200 : Ok | Cela signifie que tout va bien et que le serveur Web renvoie le contenu d’une ressource dans le corps (body) de la réponse |
| Code HTTP 301 : Moved Permanently | C’est une redirection permanente vers une URL indiquée dans la réponse (champs ’Location’). Cette redirection est considéree comme ’Google Friendly’ et n’affecte pas votre référencement naturel |
| Code HTTP 302 : Moved temporarily | C’est une redirection temporaire vers une URL indiquée. C’est moins apprécié par Google |
| Code HTTP 400 : Bad request | Cela signifie que la requête reçue par le serveur Web ne respecte pas le format défini par le protocole HTTP |
| Code HTTP 401 : Unauthorized | Cela signifie que l’accès à l’URL est sécurisée. Le serveur Web vous demande ainsi de lui indiquer un login/mot de passe |
| Code HTTP 403 : Forbidden | Cela signifie qu’un login/mot de passe invalide a été donnée pour accéder à une URL sécurisée |
| Code HTTP 404 : File not found | Cela signifie que le serveur Web n’a pas trouvé de ressource correspondant à l’URL indiquée |
| Code HTTP 500 : Internal Error | Cela signifie que le serveur Web n’a pas été capable de traiter la requête HTTP. Cela peut indiquer un problème très sérieux. |
Liste des principaux champs HTTP des réponses⚓︎
Il est utile de connaître les champs HTTP les plus connus pour les réponses :
| Content-Type | le serveur Web indique le type (’MIME type’) de la ressource qu’il renvoie (image, html, pdf...). Il peut même indiquer parfois l’encodage des caractères du contenu. Par exemple: text/html; charset=UTF-8 |
|---|---|
| Server | le serveur Web indique sa signature dans ce champ. |
| Set-Cookie | le serveur Web (souvent guidé par les lignes de code du développeur d’un site Web) peut indiquer au navigateur des valeurs de cookies. Ces valeurs seront renvoyés par le navigateur dans les requêtes futures. |
| Location | c’est le champ utilisé lors des redirections pour indiquer la nouvelle URL cible |